See which AI wins, on your own desk.
Orionfold Arena puts every move on one screen: run, compare, score, and train local AI models on one NVIDIA DGX Spark. The model, the tests, the hardware, and the results all live in one place you control. Nothing leaves the box.
pip install fieldkit[arena] Proven on the same stack
The field notes are the receipts. One builder, one Spark, a public research log anyone can read and rerun.
- Field notes published
- 56
- +13 in the works
- Words written
- 176,597
- across the whole log
- Lines of fieldkit code
- 63,840
- Python, CLI, tests
- Open models
- 8
- run and scored locally
- NVIDIA products
- 11
- used across the notes
- Throughput
- 100tok/s
- a local brain, on one Spark
Every number is a live count from the public research log, the ainative field notes. Read the notes, then rerun them yourself.
What the loop earns
Run, compare, score, train, repeat. Here is what that loop already produced on this exact stack, each a field note you can open and rerun.
0 → 154/158
It improves itself overnight
34 self-play steps on one Spark took an agent from finishing nothing to finishing almost every task. No cloud, no learned reward model, just the loop running while you sleep.
ClawGym on Spark, with self-play76% faster
Faster on your own metal
Dropping to the Blackwell-native 4-bit kernel the Spark runs in hardware decoded 76% faster than the stock server, on a smaller model file. You get speed the rented endpoint never exposes.
TensorRT-LLM on Spark$0.02
Because it is your box
A 50-run overnight research loop cost two cents of electricity. On a rented cloud the same loop bills per token and per GPU-second, so you plan carefully. On your Spark, running it is free enough to be rigorous.
Auto-research agent loopThe Orionfold line · Relay leads
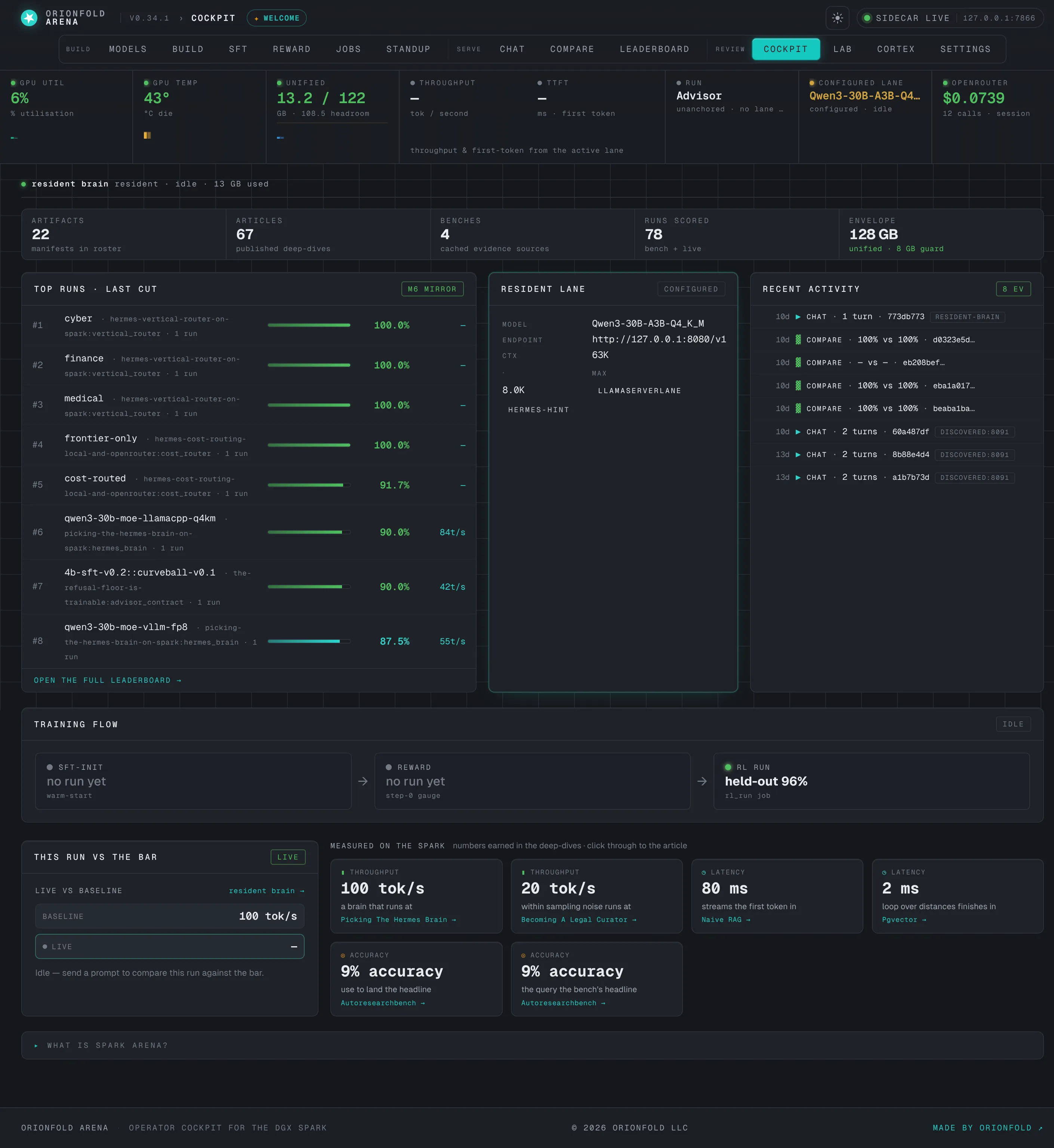
One screen over the whole loop
What it does
You have a shelf of local models and nowhere to drive them from. Arena is the instrument panel that turns that shelf into something you can fly. Four moves, one screen.
Run
Chat with a loaded model on your own box. Live GPU load, speed, and memory on one screen. Nothing you type leaves the machine.
Compare
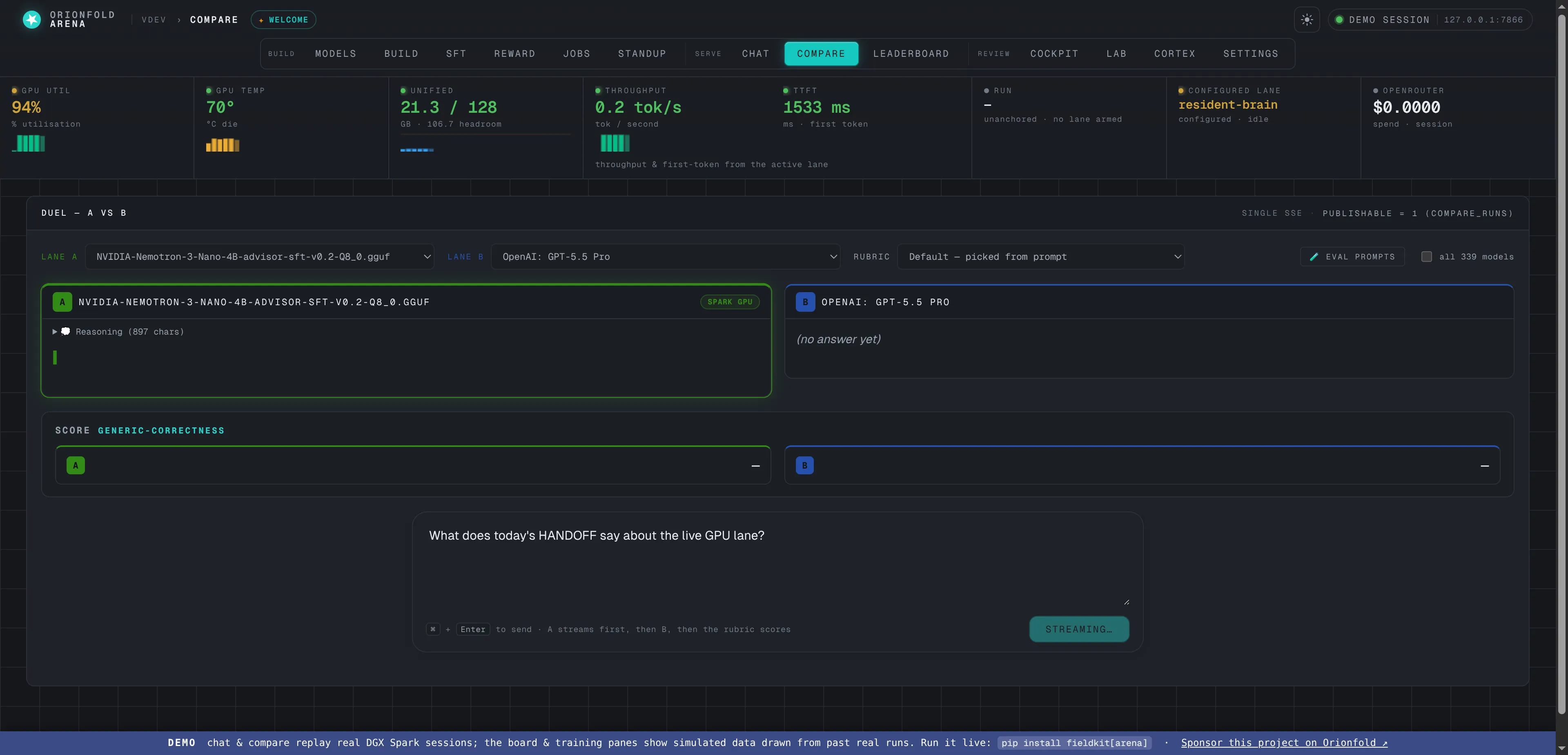
Put any two models side by side. Quality, speed, how fast the first word lands, and cost, each drawn over the run so you can see the difference, not guess it.
Score
Pick a test, send a real prompt from the chat, and the right answer sits beside the model’s answer while a grader scores it. Testing becomes one button.
Train
Queue tests and training runs overnight and wake up to a morning report. Start from where you left off, reward the good runs, and watch progress fill on one board.
A board you can publish, data you keep
The leaderboard is built from your own results, and it is safe to share. A locked-down list exports only the scores and the totals, never a prompt, an answer, or the model's working. The board is something you can publish; the data behind it stays yours.
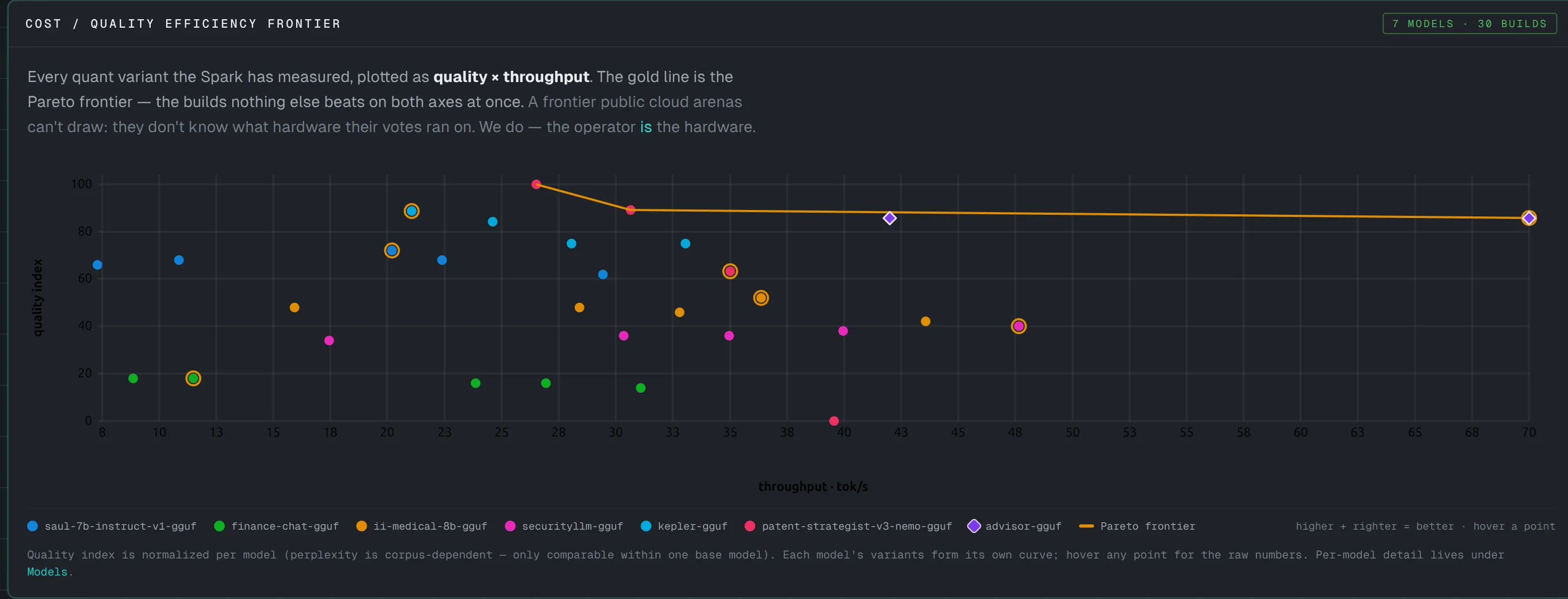
Arena plots cost against quality, so you can read at a glance which smaller model earns its place. It is the full loop a rented AI service never gives you: the model, its test data, the hardware, and the results, all in one place you control.
Get an AI team without hiring one
Own the proven box, not the parts.
Arena Field Edition turns the Spark you own into a private AI lab, delivered turnkey. It installs in one pass, proves itself on first boot with a verifiable receipt, and stays proven for a year.

Inside the screen
A few of the surfaces you drive, all on the machine under your desk.
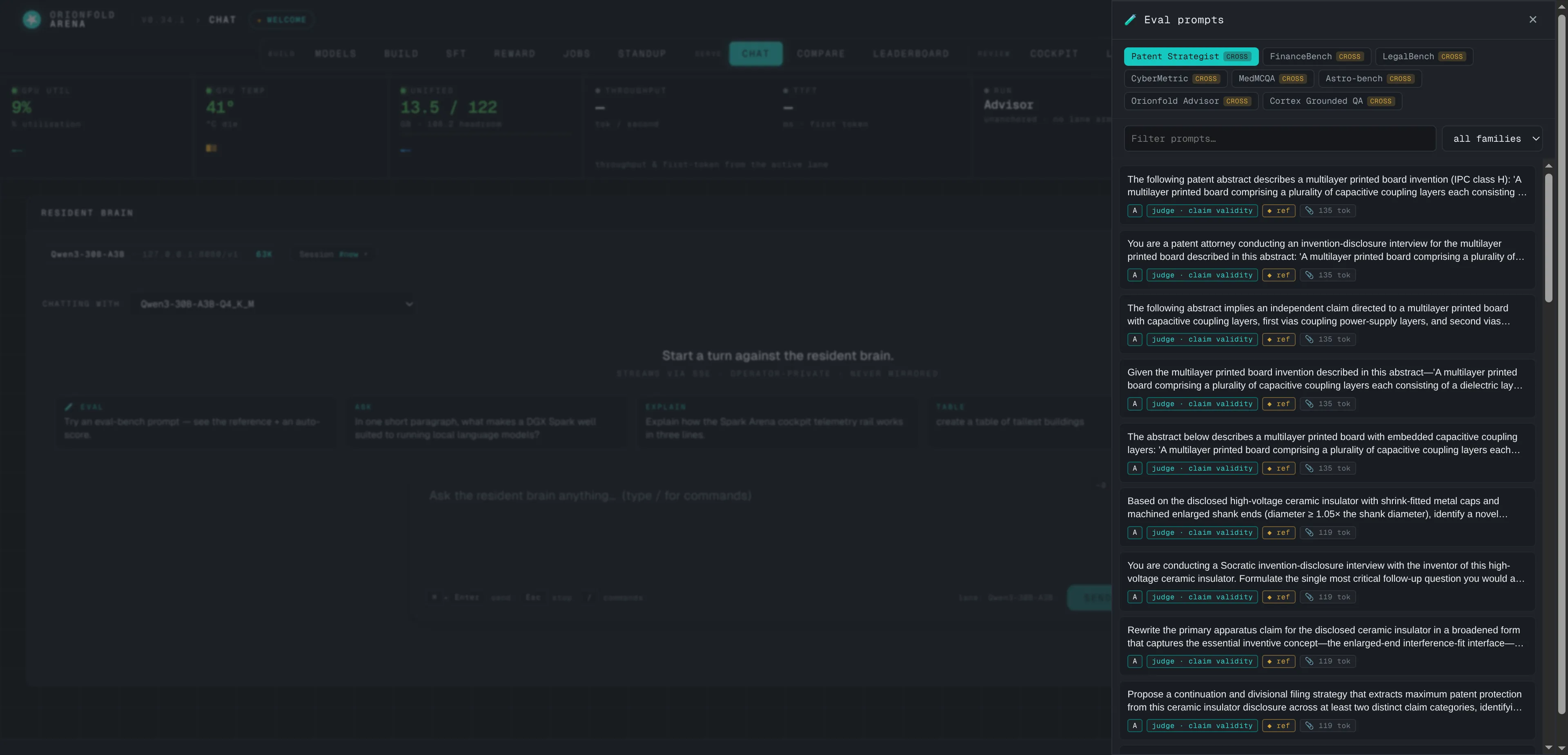
What one builder shipped on it
The proof is what one builder already did with this exact stack. Solo, on a single Spark running Arena: 14 software tools, 6 open models, 3 books, a 54-article research corpus, and 2 production sites.
~15 hours
Arena itself, built in about fifteen hours across one day and an overnight.
125 tests
Written alongside the features, over 12,733 lines of authored source.
Private by design
Nothing you type is uploaded. It is a tool you could run on a plane.
Every install runs an eval gate and writes a verifiable receipt you can read. The receipt reports the real state of the box, and the 12-month window re-gates and re-receipts every update. What you buy is the assembled, proven, kept-proven AI team, not a pile of parts you wire together and babysit.
What you get out of it
A model you own, beating one eight times bigger.
This is the payoff of the run-compare-score loop, on a locked governance test. The winner is a small model you can run on your own box, for nothing per run. The receipt is public and you can rerun it.
18 of 21
A 4B model you own, scored on the locked test. It refused all 9 trick questions and made up nothing.
8 of 21
A model eight times bigger, on the same test. It made up 3 answers the small one did not.
$0.00
Cost to run the winner, on the Spark under your desk. No account, no per-word bill.
The full receipt, config hash
552d0060f782,
is on the receipts page,
with the three honest misses and the exact test, so you can rerun it yourself.
Before you buy
The questions a box owner asks.
Arena runs on your own Spark, holds none of your data, and keeps working even if we do not. Here are the questions a careful buyer asks, answered in plain words, each backed by a page that links the code that proves it.
-
Does Arena send our evals to you?
No. Arena runs on your own Spark. Your test prompts, your model answers, and your scores stay on the box. We run no service in the middle, so there is nothing for us to see and nothing for us to hold.
See every network call -
Can I publish the leaderboard safely?
Yes. The board exports only the scores and the totals, through a locked-down list. A prompt, an answer, or the model’s working never leaves with it. You can share the board and keep the data behind it.
Read the security packet -
What if you disappear?
You keep everything. The box is yours, your data is on it, and your license works offline. If Orionfold went away tomorrow, your lab keeps running. The honest edge cases are written down too.
Read the continuity note -
Can I trust what gets installed?
Yes, and you can check it. Every release ships with a signed record of where it came from and a full parts list, and the install is checked against a fingerprint before it runs. The receipt on first boot reports the real state of the box.
See the supply chain
Get an AI team without hiring one, in the Spark you own
Arena Field Edition
Arena Field Edition turns the Spark you own into a private AI lab with an AI research teammate: agents that do real work, models that know your field, and tests that prove it. You go from running demos to shipping AI research and engineering beyond your solo skills.
The proof is what one builder already did with this exact stack. Solo, on a single Spark running Arena: 15 software tools, 7 open models, 3 books, a 54-article research corpus, and 2 production sites. That is the velocity the box unlocks.
It installs in one pass, proves itself on first boot with a verifiable receipt, and stays proven for a year, every update re-gated and re-receipted. What you buy is the assembled, proven, kept-proven AI team delivered turnkey, not a pile of parts you wire together and babysit.
$349 founding, first 25 licenses
then $499 one time, 12-month window included
After the first year, $149/yr keeps it proven: the updates, the re-run gate, and a fresh receipt. Skip it and your box keeps working, you just stop getting new proof.
Start with the free book.
Get the AI Native Business book free, and a note when we ship new Arena proof.
PDF + EPUB, plus new-proof notes
By subscribing you agree to receive the AI For Everyone digest, one email a week, no more. You can unsubscribe any time. See our privacy policy.
Drive every screen yourself.
Click through every screen in the live demo, or get the Field Edition and run the whole stack on your own Spark.
Orionfold Arena Field Edition